Utilizzando AlloyDB for PostgreSQL mi sono interessato all’algoritmo sottostante, basato su ScANN e recentemente esteso con SOAR.
In fase di indexing si costruisce una struttura per organizzare i vettori nello spazio, in modo da fare ricerca solo su sottoinsieme. I vettori vengono quantizzati e assegnati a diverse partizioni tramite SOAR. Analizziamo
Ho i dati in un database vettoriale e una query $q$. Voglio ritornare i $k$ più vicini a $q$. Facendo una ricerca lineare ottengo tutti dati esatti ma è inefficiente (intractable) data la maledizione della dimensionalità. Approssimo l’esattezza per guadagnare efficienza, da qui Approximate Nearest Neighbor
Spill Tree
Replicazione dei dati per ridurre errori di partizionamento.
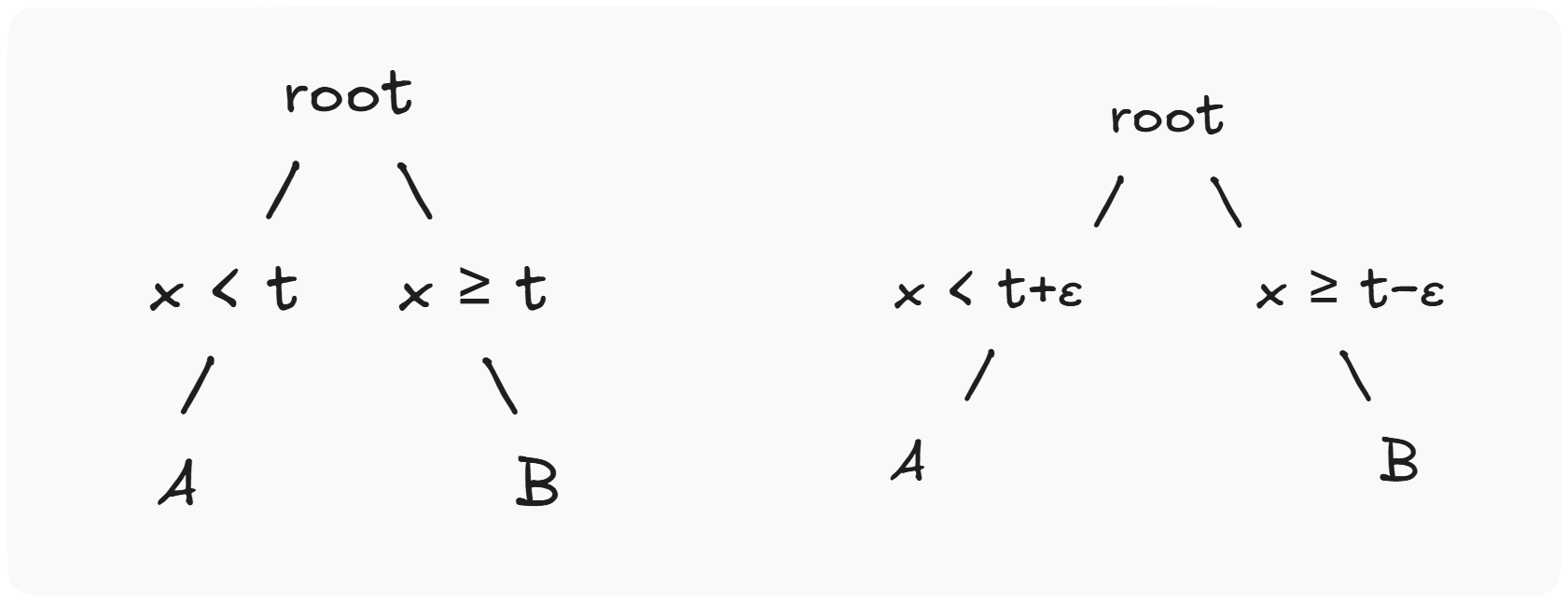
Qui vediamo $t$ come un iperpiano di separazione, divide lo spazio in due regioni. Si introduce un overlap in modo i punti vicini al confine siano replicati sia in $A$ che in $B$
Ma la complessità è esponenziale, se a ogni livello dell’albero un punto $x$ cade nella zona di overlap viene duplicato in entrambi i figli e comparirà $2^h$ volte.
Vector Quantization
Approssimo i valori dei vettori con dei centroidi. Questo processo ritorna due oggetti: codebook e funzione di assegnazione
$$C \in \mathbb{R}^{c\times d} \tag{1}$$
è una matrice di $c$ righe, ognuna un vettore in $\mathbb{R}^d$, quindi ogni riga è un centroide.
$$\pi(v):\mathbb{R}^d \mapsto {1,\dots, c} \tag{2}$$
La funzione di assegnazione fa si che ogni vettore sia assegnato al centro più vicino. Così in fase di query calcoliamo il prodotto scalare tra $q$ e tutti i centroidi , ordiniamo per punteggio e recuperiamo i punti di quelle partizioni.
Questo non avviene gratis, perchè sostituendo $x$ con il suo centroide introduciamo dell’errore.
Residuo
Ciò che perdiamo sostituendo $x$ con il suo centroide
Più è grande e positivo più sottostima il punteggio reale e la partizione giusta può non essere visitata. Questo accade quando il residuo $r$ è allineato con la query $q$
Spilling with Orthogonality-Amplified Residuals
Per evitare che un punto $x$ venga perso durante la ricerca lo assegniamo a più partizioni. Ma come scegliamo a quale altra partizione?
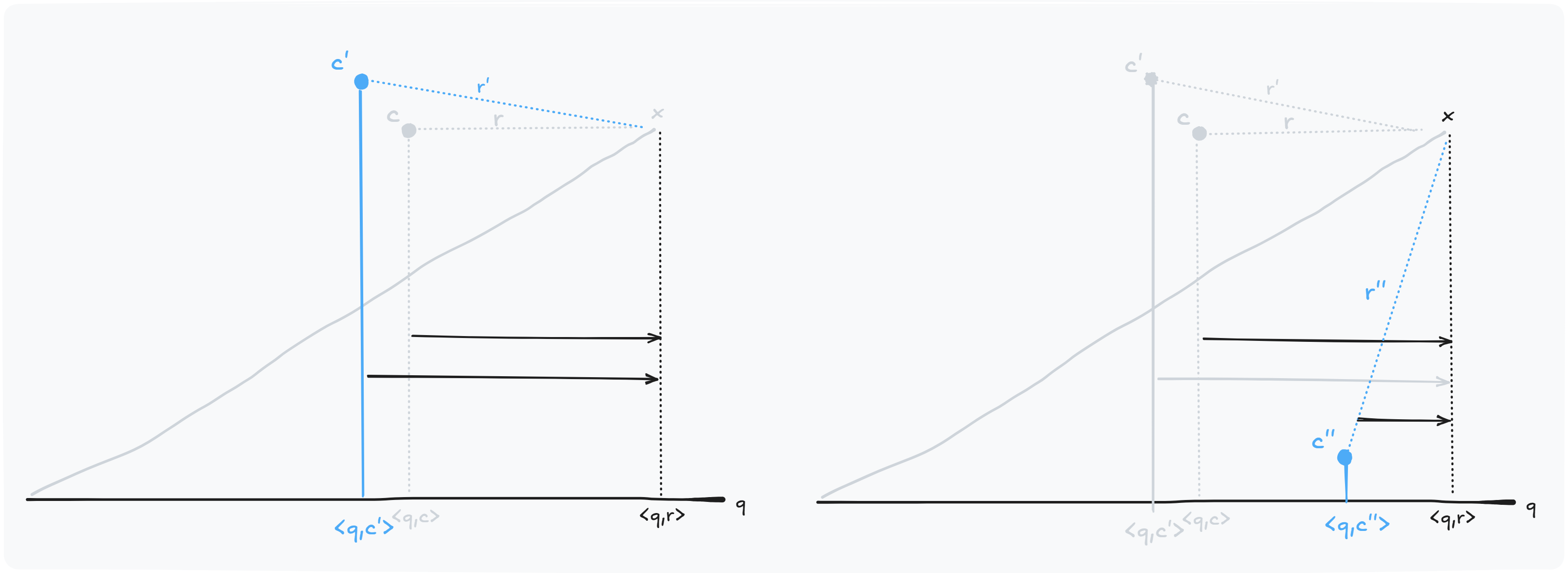
A sinistra, vediamo che scegliendo $c’$, il nuovo residuo $r’$ ha una direzione simile a $r$. A destra viene scelto $c’’$ tale che il residuo $r’’$ sia quasi ortogonale a $r$
Così almeno una delle due approssimazioni mantiene un buon punteggio rispetto a $q$. Per rispondere alla domanda precendete, scegliamo il centroide tramite una loss che minimizza l’errore di quantizzazione e penalizza l’allineamento tra residui.
$$ L(r’, r, Q) = \mathbb{E}_{q \in Q} \left[ w(\cos\theta), \langle q, r’ \rangle^2 \right] $$
dove:
- $r = x - c$ è il residuo della prima assegnazione
- $r’ = x - c’$ è il residuo candidato
- $q$ è una query $\in Q$1
- $\theta$ è l’angolo tra $q$ e $r$
- $w(\cos\theta)$ pesa di più i casi in cui l’errore originale è alto, quindi $r$ è allineato con $q$
Tutte queste assegnazioni multiple aumentano i costi di memoria e indicizzazione in modo lineare con il numero di copie per punto. Viene dimostrato che già una seconda assegnazione è sufficiente a coprire la maggior parte dei casi, ulteriori assegnazioni portano benefici marginali rispetto ai costi.
Link al paper ufficiale: https://arxiv.org/pdf/2404.00774
Si può considerare $Q$ come campione rappresentativi dei casi reali, la distribuzione delle query che ci aspettiamo durante l’uso del sistema ↩︎